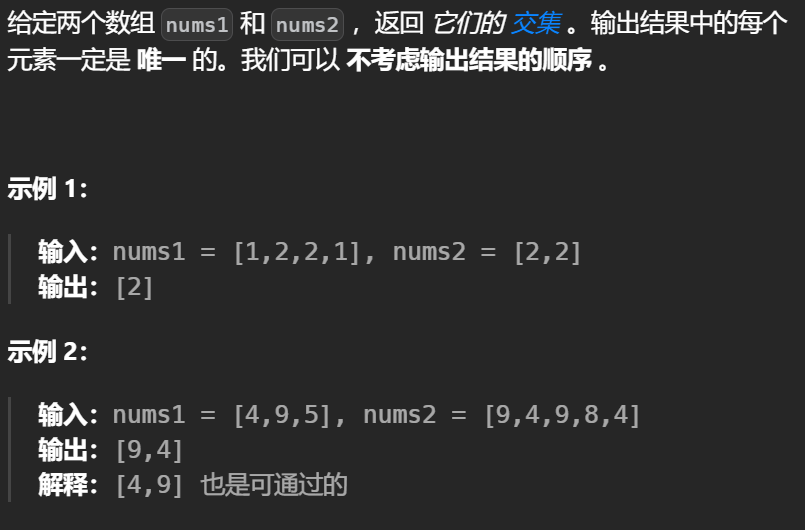
我的思路
两者排序完先将nums1扔进哈希表,在遍历一遍nums2把找到的放入ans即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| struct hashTable{
int key;
UT_hash_handle hh;
};
struct hashTable* set=NULL;
void clearHashTable(){
struct hashTable *current,*tmp;
HASH_ITER(hh,set,current,tmp){
HASH_DEL(set,current);
free(current);
}
}
int cmp(const void* a,const void* b){
return *(int*)a-*(int*)b;
}
int* intersection(int* nums1, int nums1Size, int* nums2, int nums2Size, int* returnSize) {
clearHashTable();
*returnSize=0;
qsort(nums1,nums1Size,sizeof(int),cmp);
qsort(nums2,nums2Size,sizeof(int),cmp);
for(int i=0;i<nums1Size;i++){
if(i>0&&nums1[i]==nums1[i-1]){
continue;
}
struct hashTable*tmp=NULL;
HASH_FIND_INT(set,&nums1[i],tmp);
if(tmp==NULL){
tmp=malloc(sizeof(struct hashTable));
tmp->key=nums1[i];
HASH_ADD_INT(set,key,tmp);
}
}
int* ans = malloc(sizeof(int) * (nums1Size < nums2Size ? nums1Size : nums2Size));
for(int i=0;i<nums2Size;i++){
if(i>0&&nums2[i]==nums2[i-1]){
continue;
}
struct hashTable*tmp=NULL;
HASH_FIND_INT(set,&nums2[i],tmp);
if(tmp!=NULL){
ans[(*returnSize)++]=nums2[i];
}
}
return ans;
}
|
官方题解

由这个,我们创建一个1001大小的数组,遍历nums1时把有的值变为1,遍历nums2时,当值为1时放入ans即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| int* intersection(int* nums1, int nums1Size, int* nums2, int nums2Size, int* returnSize) {
int hash[1001]={0};
int* ans = malloc(sizeof(int) * (nums1Size < nums2Size ? nums1Size : nums2Size));
int j=0;
int count=0;
for(int i=0;i<nums1Size;i++){
if(hash[nums1[i]]==0){
hash[nums1[i]]=1;
}
}
for(int i=0;i<nums2Size;i++){
if(hash[nums2[i]]==1){
ans[j]=nums2[i];
j++;
count++;
hash[nums2[i]]--;
}
}
*returnSize=count;
return ans;
}
|




